
At Report URI we're on the receiving end of several billion reports per month and handling that many reports requires a lot of processing. From analysing to see if the JSON payload is valid, checking it contains the correct fields and normalising the values, there are quite a few tasks that need to be completed before we can store the report payload. Here's how we offloaded most of that work to Cloudflare.
Cloudflare Workers
Cloudflare recently announced that workers are now generally available to all of their customers. We already used Cloudflare for a great many things at Report URI, including their CDN, Firewall, Rate Limiting and more, and now we can add one more item to that list, Workers. Allowing you to execute code on Cloudflare's edge nodes, we could shift a lot of our processing form our own origin servers, based in San Francisco, to Cloudflare's servers that are distributed all around the world. This means our code executes closer to our users, but more specifically closer to our user's visitors, who are the ones sending us reports. You can read more details about Cloudflare Workers in their launch blog and in their documentation but for now I want to dive into what it is we're doing with Workers already.

JSON Processing
When a browser sends a report to us, we receive a JSON payload sent via a POST request. That request contains all of the information we need to process the report into the appropriate account and there are various steps that we go through. Historically all of this processing took place on our servers in San Francisco but now, an increasingly large amount of it is taking place somewhere much closer to where you're reading this blog post from. Our Cloudflare worker is not only going to be taking on increasingly larger amounts of work in terms of processing incoming reports, it will also be handling a larger and larger portion of our the traffic volume as time goes by.
One of the first things that the worker checks for when processing a report is that the JSON payload is present and valid. If we haven't received valid JSON then there's no point even passing the request to our origin servers. This would incur the penalty of the network latency from whichever Cloudflare data centre you were closest to through to our origin, just to find out the request is bad and for us to return a 400 in response. Not only that but we took up resources on our origin for something that we could never do anything about.
try {
var csp = await req.json()
} catch (err) {
return buildError('The JSON payload was not valid.')
}
if (typeof(csp) !== 'object') {
return buildError('The JSON payload was not valid.')
}If the JSON isn't valid, we will tell you in the region of 200 ms from the worker instead of a lot longer when you're routing through to our origin, depending on how far away you are. For the purpose of the remaining tests/demos, requests to my reporting address are handled by the worker and requests to Troy's reporting address are handled by our origin. I'm currently sat in Köln Bonn Airport writing this blog post whilst I wait for my flight so the requests to my reporting address are being handled by the worker in Frankfurt, which Google Maps tells me is 140.54 km (87.33 mi) away. The request to Troy's address go to our origin in San Francisco which is 9,013.82 km (5,600.93 mi) away, again according to Google Maps. Let's see what difference that makes.
scotthelme@MacBook-Pro:~$ curl -d "{\"not json\"" -H "Content-Type: application/csp-report" -X POST -w "@curl-format.txt" https://troyhunt.report-uri.com/r/d/csp/enforce
The input is not an array
time_namelookup: 0.005285
time_connect: 0.036422
time_appconnect: 0.152999
time_pretransfer: 0.153314
time_redirect: 0.000000
time_starttransfer: 0.153406
----------
time_total: 0.871076
scotthelme@MacBook-Pro:~$ curl -d "{\"not json\"" -H "Content-Type: application/csp-report" -X POST -w "@curl-format.txt" https://scotthelme.report-uri.com/r/d/csp/enforce
The JSON payload was not valid.
time_namelookup: 0.005302
time_connect: 0.070079
time_appconnect: 0.191080
time_pretransfer: 0.191398
time_redirect: 0.000000
time_starttransfer: 0.191490
----------
time_total: 0.253446
That's a pretty significant performance increase, shaving over 600ms off the response time! If the report payload is valid and we can continue processing it, then it needs to be prepared for being stacked in our Redis cache which the consumers feed off. Every 10 seconds a consumer will grab the contents of the Redis cache and process them into Azure, allowing us a small time window to massively de-duplicate reports on the way in and to stack them more aggressively after normalisation. With the consumers doing this later they lose some information in the original POST request, mainly the subdomain the request was made to, which indicates the account the reports need to go to, and the GET parameters of the request, which indicate which type of report it should be and the disposition of the policy. To get around that we added various flags to the JSON payload when we ingested reports and stored them in Redis, the Cloudflare worker also needs to take on this responsibility.
csp['flag_reportType'] = path[2];
csp['flag_appName'] = path[1] === 'default' ? 'd' : path[1]
csp['flag_reportToken'] = new URL(req.url).hostname.replace('.report-uri.com', '')
With that taken care of, we can offload a lot of our basic processing into the Cloudflare worker. If the worker is already being executed, it makes sense to do more work there!
Answering CORS pre-flights
In recent iterations of Chrome and Firefox the browsers have started to send a CORS pre-flight request before dispatching a report. Whilst technically a violation of the SOP (the reports are a non-whitelisted content-type sent as a dangerous POST request) we have gotten away with sending CSP reports for quite some time without considering CORS, but that's now changed. To check that the browser is permitted to send the report to the specified endpoint, which is cross-origin, it has to send what we refer to as the CORS pre-flight. This is a HTTP OPTIONS request sent prior to the actual HTTP POST being made with the JSON payload. If the 3rd party origin answers the CORS pre-flight correctly then the browser will dispatch the report. The CORS pre-flight looks like this:
OPTIONS /r/d/csp/enforce HTTP/1.1
Host: scotthelme.report-uri.com
...
Access-Control-Request-Method: POST
Access-Control-Request-Headers: Content-Type
Upon receiving this request the server must respond with suitable information that allows the browser to follow the pre-flight with the actual request itself. To do that, we set a series of headers in the response and pass the information back as the values of those headers.
Status: 200
Access-Control-Allow-Headers: Content-Type
Access-Control-Allow-Methods: POST
Access-Control-Allow-Origin: *
Access-Control-Max-Age: 1728000
...
Here we have told the browser that any origin is allowed to send reports to us with Access-Control-Allow-Origin: *, we've told the browser it is allowed to make a POST request, to set a Content-Type header and to remember these settings for 1,728,000 seconds so it doesn't need to make another pre-flight before sending further reports.
With this the browser will now be able to send the CSP report to us. Whilst the Access-Control-Max-Age header will allow the browser to cache these settings for a short period of time, there are still an awful lot of CORS pre-flights that hit our origin. What's worse, some browser cap the max-age value so will send another pre-flight a lot sooner. With the Cloudflare Worker we can answer the CORS pre-flights from Cloudflare's edge right next to the user rather than shlepping all the way across the world to find out that you were allowed to send the report.
else if(req.method === 'OPTIONS') {
let newHdrs = new Headers()
newHdrs.set('Access-Control-Allow-Origin', '*')
newHdrs.set('Access-Control-Allow-Methods', 'POST')
newHdrs.set('Access-Control-Allow-Headers', 'Content-Type')
newHdrs.set('Access-Control-Max-Age', 1728000)
return new Response('OK', {headers:newHdrs})
}With this simple piece of code we can respond to any and all CORS pre-flights with significantly better performance due to the lower network latency and again, alleviate load on our origin doing mundane tasks.
scotthelme@MacBook-Pro:~$ curl -X OPTIONS -w "@curl-format.txt" https://troyhunt.report-uri.com/r/d/csp/enforce
time_namelookup: 0.005272
time_connect: 0.031799
time_appconnect: 0.141692
time_pretransfer: 0.142104
time_redirect: 0.000000
time_starttransfer: 0.873945
----------
time_total: 0.873963scotthelme@MacBook-Pro:~$ curl -X OPTIONS -w "@curl-format.txt" https://scotthelme.report-uri.com/r/d/csp/enforce
OK
time_namelookup: 0.005119
time_connect: 0.045036
time_appconnect: 0.175286
time_pretransfer: 0.175672
time_redirect: 0.000000
time_starttransfer: 0.225194
----------
time_total: 0.225249Again we're seeing a reduction in the response time of over 600ms! Shaving the network latency off from the Cloudflare edge node to our origin is pretty significant. This saving could be smaller if you were in , let's say America, but it could also be a lot larger if you were in Australia (hi Troy!). Depending on where in the world you are there are savings to be made, one way or another.
Reducing our infrastructure
Right now we have a series of ingestion servers that take care of all of the above tasks, and more, before inserting the reports into Redis. Given the high volume of traffic we receive we need a to have a fair amount of processing power on tap to handle them. We also need to over provision on these ingestion servers because whilst we can scale quickly and easily, CSP reporting is an incredibly spiky business. A new site can come on board with a bad policy and quadruple our load in the blink of an eye. During that time we don't want to have a degraded service so we have a little spare capacity already raring to go at all times. The use of Cloudflare Workers fundamentally changes this concept. Here's our current infrastructure at the front end:

Once we've fully transitioned to using Cloudflare workers, which we're already making great progress on, our infrastructure will look just slightly different.

Whilst that might not seem like a significant change it removes a piece of complexity that we currently have to manage. Right now if we have a spike in reports we have to scale our ingestion servers, either vertically or horizontally, to respond to the demand. We also have to manage the servers themselves, patching them and updating them as we go. With Cloudflare workers we have neither of those concerns and we're left with just our Redis cache to manage which is capable of handling orders of magnitude more traffic than it does right now.
Current utilisation
Over time we worked up to running 100% of traffic through the worker and and have already noticed a pretty nice reduction in traffic to our origin and the consumption of a smaller amount of resources. The basic tasks of answering CORS pre-flights and pre-processing JSON alone are enough to make a difference, it's going to be pretty interesting when we announce some more of the changes we have coming! For now, here's how our utilisation of Workers looks over the last week.
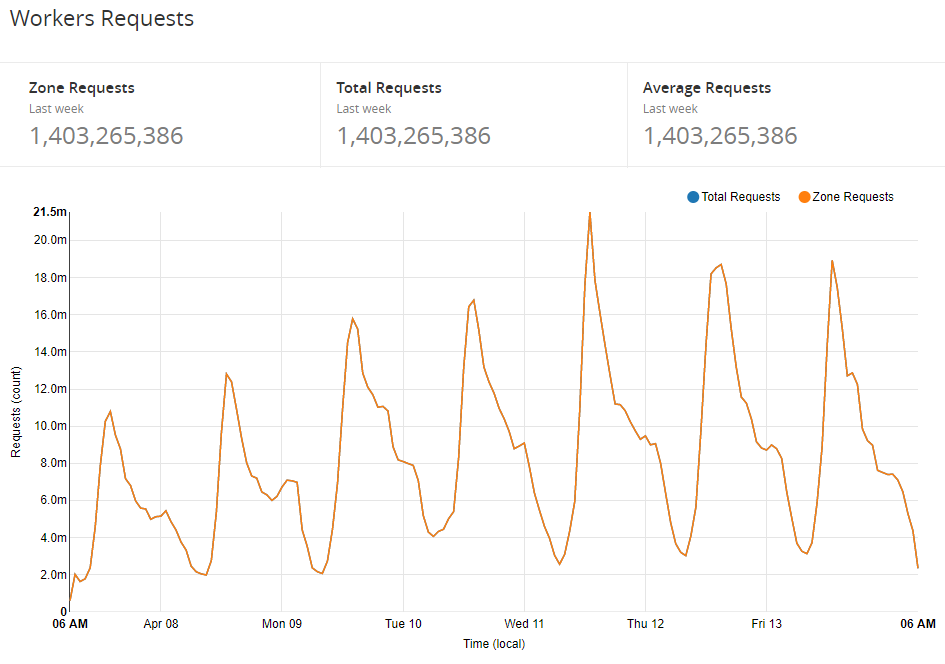
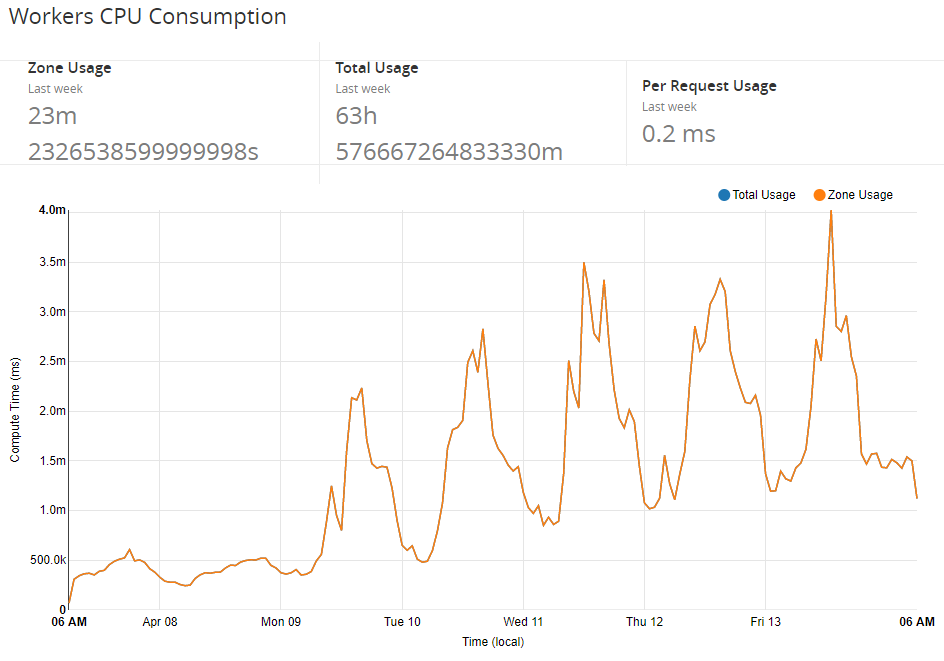
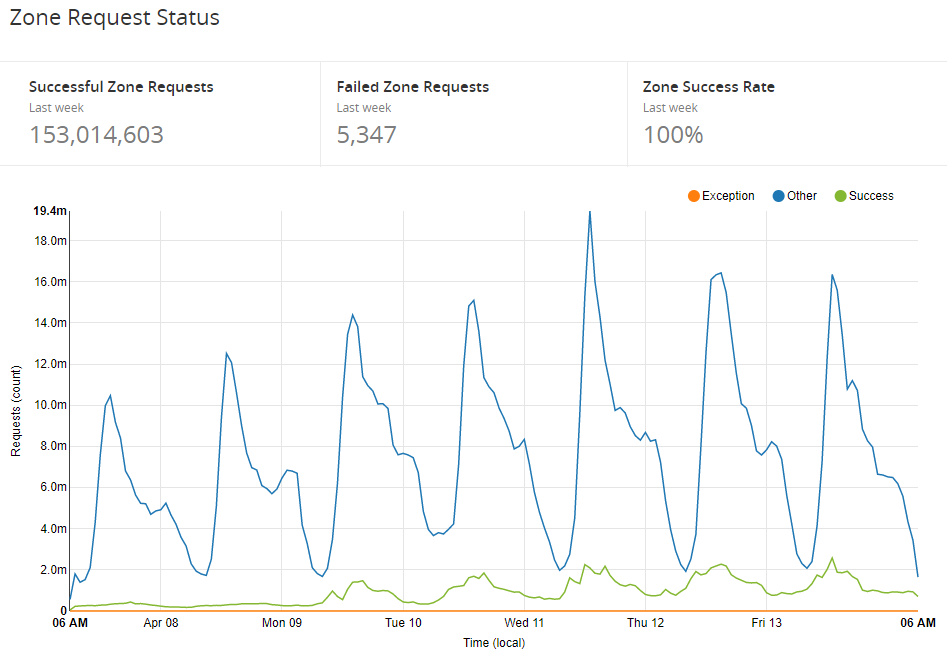
Future plans
This is just our introduction to Cloudflare Workers and we're starting with the simple tasks while we come to terms with the more advanced capabilities they have. Right now our consumers feed out of our Redis cache and do further filtering requested by the user, things like stripping a path, filtering noise and a lot more. Those settings are per user and can't be applied globally by the worker, but we're looking to move that logic to Cloudflare's edge too. We can store a large amount of configuration data in the actual code itself and also expose user configuration to the worker via a secure API call to the origin. If a worker is executed frequently enough then it will reside in memory on Cloudflare's servers and will retain global variables across executions. This mean it could build up a filter set over time for commonly requested users and drop reports based on those without ever hitting our origin. We're not only planning on how we can use Cloudflare workers, we're also planning on how you can use them too. Believe me when I say we have some awesome things coming very soon with Cloudflare workers!