
We recently launched a brand new version of Report URI and as part of that launch we moved from our .io domain to our .com domain. It's such a simple thing to do, moving from one domain to another, all you need to do is issue a permanent redirect...
The plan
The plan was simple, we were going to bring up a brand new infrastructure behind the .com domain and then on launch day we'd just redirect all traffic from the .io to the new .com domain, easy! Except things are never easy, are they. We hit quite a few bumps along what I thought was going to be a pretty smooth road and I'm happy to say that there was minimal impact to the launch or our customers during the transition.
A 301 isn't good enough
On launch day we were going to ease into things by flipping the switch and issuing a 302 to all traffic hitting our .io domain. A 302 is a temporary redirect and means the browser will not cache the redirect or remember it in the future. This was a great way to test things out and if anything went wrong for any reason we could drop the redirect and all the traffic would happily go back to the .io domain. If things looked good and there were no issues then we could switch the 302 for a 301 which is a permanent redirect. The benefit of this is that the browser will remember it for a period of time and not keep hitting the .io domain to get redirected, it'd go to the .com domain instead. Great! There was however one little quirk with the way that a 301 and 302 redirect work. When you're issuing a GET request, everything is just fine.
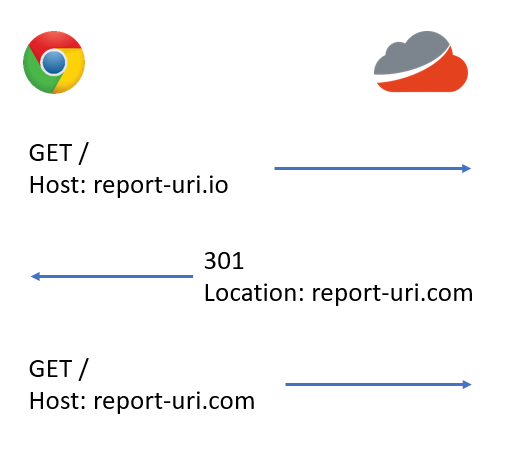
That all looks good, right? Now look what happens when we change the HTTP method...
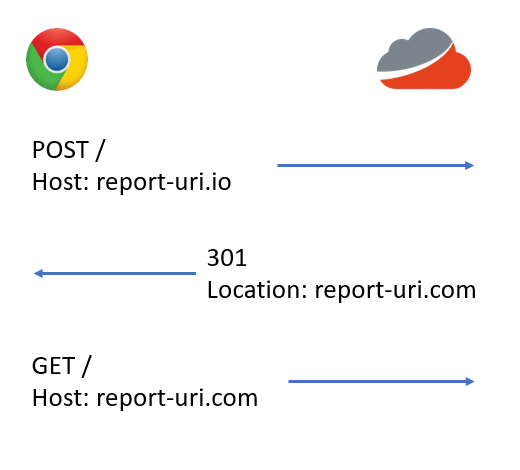
The difference there is really subtle and you may have to look twice to spot it, but as minor as that change is, it changes everything. The problem is that when you use a 301 or 302 redirect the browser will change the method on the redirect to be a GET request, even if the original method was a POST request or any other type of request. In the context of our reports this essentially disables reporting as we lose the JSON payload sent in every single report once the browser fires them again as a GET request. We needed to use an alternative redirect mechanism.
Say hello to 307 and 308
There are another 2 status codes that you can use for redirects that mirror the functionality of a 301 and 302 with one key difference, they do not allow the HTTP method to be changed on the redirect. A 307 is a temporary redirect and a 308 is a permanent redirect where a POST request will be followed by another POST request after redirecting. This solved our problems and the 307 was now going to take the place of the 302. There was no need to use both because a 307 will satisfy any HTTP method, including GET, so to keep things simple we just rolled with a single status code.
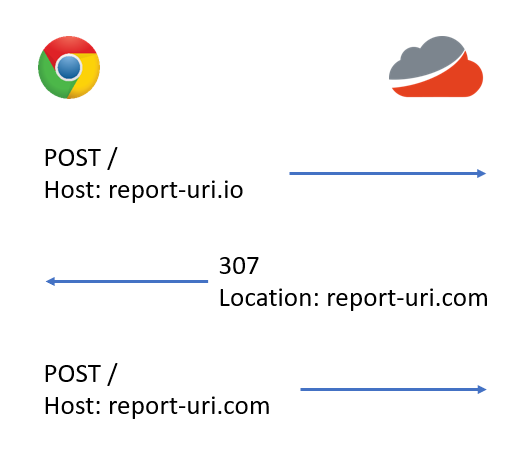
This now means that all traffic, including those crucial reports, will be properly redirected from the old domain to the new domain without any problem. Once we were happy that everything was running smoothly we could switch the 307 to a 308 and the browser would start to cache the redirect, alleviating load on our infrastructure as we wouldn't be doubling up on each request by serving redirects. Funny thing though, when we switched to testing a 308, this happened.
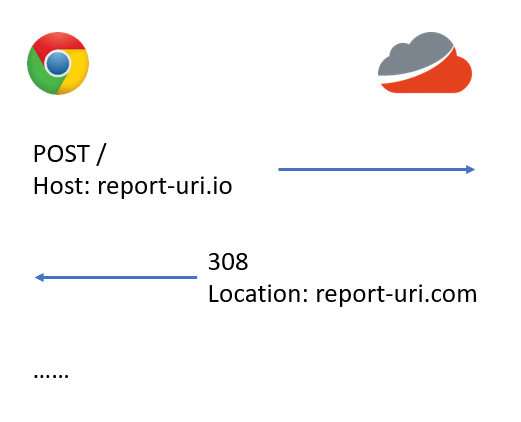
The browser stopped following the redirect, just like that. We debugged the crap out of this and after spending more time on it than I should probably admit, it turned out to be a bug in Nginx and nothing that we'd done! Don't you love it when it's not your fault? There was one crucial line in the Nginx docs that summed up why this wasn't working as expected.
The code 308 was not treated as a redirect until version 1.13.0.
At the time of writing 1.13.0 has only just hit mainline and the latest stable version is 1.12.2, so we had a version of Nginx that wasn't treating a 308 as a redirect, it looked like this.

On a 308 response Nginx was not including the Location header, so of course the browser wasn't following it, it wasn't there! This represents a problem that kind of is and isn't a problem. We wanted the 308 for a few reasons; it keeps the HTTP method as POST which is essential, it alleviates load on our infrastructure because the browser typically caches the 308 for up to 30 days and a cached redirect is faster to execute than one that hits the wire which improves performance. Without the 308 we couldn't have any of those things.
Offloading the redirect load
One of the great things about using a CDN provider is that you can get them to do things on your behalf. As part of the new launch we'd switched our CDN provider from Incapsula to Cloudflare and I deployed some Cloudflare page rules in preparation for the domain migration. Unfortunately when deploying a page rule to forward traffic there are only two options available, the 301 and 302.
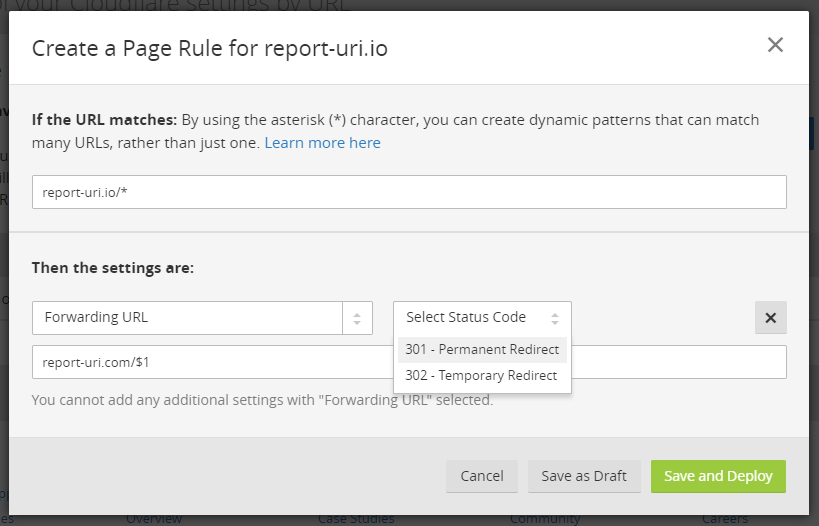
This wasn't ideal because I could redirect the UI traffic hitting our website with a 301 but reports being sent as a POST request to our subdomains would have to hit our origin to be redirected, incurring costs and latency. No problem though, I got in touch with our account manager and we were quickly advised we could harness a feature called Edge Side Code. The feature is covered in a whitepaper but in essence allows us to deploy logic at Cloudflare's edge to process requests. With this it was simple to deploy a 308 globally across our .io domain and Cloudflare took the load off our origin.
@Cloudflare took over responsibility for returning a 308 to all traffic to @reporturi's old .io domain yesterday. pic.twitter.com/Wz8roit2au
— Scott Helme (@Scott_Helme) November 9, 2017
That's the analytics graph for our .io domain and as you can see up until the rule was deployed, all traffic was uncached, meaning it was hitting our origin. As Cloudflare started deploying the Edge Side Code at the POPs around the world they started to pick up more and more of the load until eventually they were answering all requests to the .io domain from their edge, meaning we saw none of them. There were a few significant things about this and the performance of a faster redirect was one of them but at our scale even answering a request with a simple 308 takes up resources. With Cloudflare now handling that we could decommission our old .io infrastructure and save on the costs associated with that. Just look at how much bandwidth we're saving on 308 responses alone. 58GB of empty responses!

Up, up and away!
One of the phenomenal things in the first week since launch is just how much traffic is picking up. On launch day I was tracking our usual report numbers which were around 90,000 reports per minute at peak times.
Currently approaching our busy period. On a typical day we max out at just over 90k reports per minute! 😎 pic.twitter.com/HX35ILZSIF
— Scott Helme (@Scott_Helme) November 1, 2017
It was great to see the new infrastucture picking up the full load of the site after the migration but even more for me because we were actually running on less infrastrucutre than we were before. The v2 deployment was significantly more efficient and had some massive changes, but more on those in another blog. It is however a good job because not even 2 days later we were already seeing some of our new customers delivering all of their reports to us.
Impressive to watch how fast @reporturi is growing, now up to 160k reports per minute. @Scott_Helme and @spazef0rze have done awesome work! pic.twitter.com/sLrIybzQaU
— Troy Hunt (@troyhunt) November 2, 2017
That's almost double the amount of traffic in a little under 2 days, and things continued... Just a few days after that we'd almost tripled traffic again.
Amazed at how quickly @reporturi is growing, we're currently logging up to 450k reports per minute! pic.twitter.com/nASMdFJLy2
— Troy Hunt (@troyhunt) November 6, 2017
To put that number another way it's roughly 7,500 reports per second. Insane. Of course at those rates it didn't take us long to hit our first big milestone.
Only a week in since the big V2 launch, we just smashed through the first BILLION reports on @reporturi! pic.twitter.com/Exs7Svb6Tm
— Troy Hunt (@troyhunt) November 8, 2017
Our migration was a success, the traffic numbers are continuing to climb and so far we've had a pretty smooth ride, all things considered. I'm going to be doing a whole heap of followup posts about the new features we're leveraging at Cloudflare, how we built out the infrastructure to handle billions of reports per month and much, much more. We have some truly awesome features coming for the site and another product to announce early next year so stay tuned.