
It's no secret that we use Cloudflare Workers extensively at Report URI and once you're using a Worker, you can keep adding more functionality to it. Here's our latest update on the things we're doing with our Worker!
Cloudflare Workers
There's plenty of documentation out there on Cloudflare Workers and I've done a lot with them including a Security Headers worker, buffering HTTP POST requests, JSON pre-processing and CORS pre-flights and a basic HTTP proxy. Workers are billed per execution so once you've triggered a Worker execution, the cost doesn't change whether the Worker does 1 thing or 5 things (of course within the resource limits, which are generous). That means it makes sense to fully utilise the Worker for any task that it's well suited to do and it can do some pretty advanced things!

Report URI and quota management
Users on Report URI sign up and receive a monthly quota of reports that we will process for them. This starts at 10,000 reports on the free tier and goes up 5,000,000 reports on the largest standard plan. We have Enterprise customers on 100,000,000 reports or more! No matter what plan you're on though, there's a limit to how many reports we will process for you and of course it's a fairly regular occurence for users to go over that quota. We didn't want any surprise bills for our customers so once you're over quota we stop processing reports into your account and don't charge you anything extra. The problem is that once a user is over quota the reports don't stop being sent. If reports continue to be sent then we have to continue to receive and process them. Yes, we are doing a lot less processing, as we'll throw them away at our earliest opportunity, but at our volume that's still a significant amount of work!
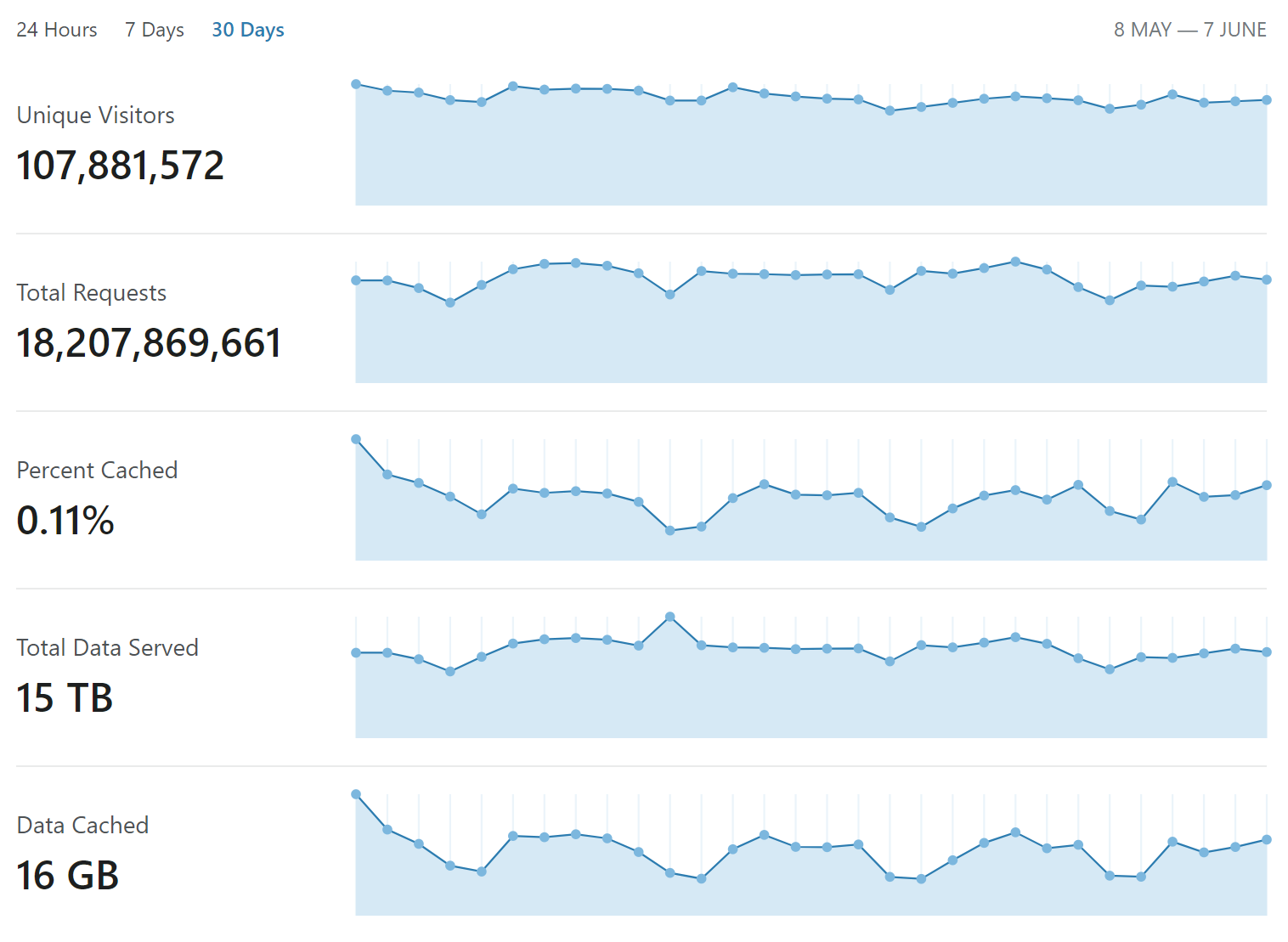
What'd we'd like to be able to do is stop these reports from hitting us and avoid the cost of dealing with them at all. Now, we can't stop them being sent, so they're coming to us one way or another. But we wondered if the Worker could help us out here.
Maintaining state in a Worker
I hinted at a few options here in a previous blog post and one of them included keeping config in the Worker source itself. This wasn't suited to our needs as our users can go over quota and be placed on 'lockdown' (our internal term) at any time, or upgrade and have their lockdown removed. No, this state had to be maintained dynamically in the Worker itself. This mean that we needed to expose this information to the Worker for it to be able to query whether or not a user was on lockdown when it received a report destined for their account. Now, the Worker can't make that call to our origin for every inbound report as that'd introduce just as much overhead as dispatching the report without checking. The Worker needed to remember.
async function getLockdownStatus(user) {
let statusCheck = await fetch('https://report-uri.com/worker/get_lockdown_status/' + user)
let lockdownCacheTime = 60 * 60 * 1000
let lockdown = false
if (statusCheck.status === 429) {
lockdown = true
}
lockdownStatus[reportToken] = {'lockdown': lockdown, 'expires': (new Date).getTime() + lockdownCacheTime}
}With this request the Worker can call back to our origin and ask for the lockdown status of a user. Upon retrieving that status it will store it in a global lockdownStatus object for an hour which can then be referred to on every execution of the Worker. This means that if a user does go over their quota, the next time a Worker requests their lockdown status it will come back as being flagged for lockdown and the Worker can simply stop passing the reports back to us.
...
// early in the code
if (await userIsOverQuota(user)) {
return buildError('Over Quota', 429)
}
...
async function userIsOverQuota(user) {
if (typeof(lockdownStatus[user]) === 'undefined') {
await getLockdownStatus(user)
} else if (lockdownStatus[user]['expires'] < (new Date).getTime()) {
await getLockdownStatus(user)
}
if (lockdownStatus[user]['lockdown']) {
incrementRejectCount(user)
return true
} else {
return false
}
}This is awesome for us now because as soon as a user goes over quota we can update the Workers pretty quickly and then have them stop sending us the reports for the remainder of the month or until the user upgrades to increase their quota. That said, it wasn't as awesome as I wanted it to be and there was something that needed further improvement.
This global object was only maintained for the life of the Worker and that meant if the worker was killed and spawned again for any reason it'd have to fetch the lockdown status for all of our users again. Also bear in mind that Workers are run per server in each of Cloudflare's 182 datacentres so there are potentially hundreds (or maybe thousands?) of instances, all of which need to maintain their state. This was causing a lot of traffic to our origin to fetch the lockdown status of users and whilst it was better than sending all of the reports, I still wanted to push it a little more.
Using the HTTP cache
When the worker calls back to our origin to check the lockdown status of a user, we simply return an empty 200 or 429 based on the status of the user. A simple HTTP request and HTTP response, which is a prime candidate for being cached! Using the cf property on a request you can control Cloudflare features including the cache.
let statusCheck = await fetch('https://report-uri.com/worker/get_lockdown_status/' + user, { cf: { cacheTtlByStatus: {"200-599": httpCacheTime} } })By setting the cf property and manualy setting a cacheTtlByStatus we're overriding whatever the default behaviour would have been and forcing this response to be cached for the number of seconds specified. The big difference here is that the HTTP cache is run at a datacentre level and not per server like the object cached in the Worker itself. This means if a Worker spins up and doesn't have the lockdown status cached locally it can issue the request to our origin but have a really good chance of getting a hit in the HTTP cache, preventing the request form hitting our origin! This 'double layer' of caching has removed all but the most essential lockdown status requests to our origin and has allowed for a significant reduction in load.
An acceptable delay
The caching above does of course introduce a small delay in both applying a lockdown and removing a lockdown from a user. Given the significant advantages of this approach and the load it removes from our origin, this seems like a reasonable tradeoff. Once a user is placed on lockdown the update will slowly start filering out into the caches and then Workers at Cloudflare datacentres around the world and results in a surprisingly smooth decline in traffic for that user over the period of a couple of hours. The same also happens when a lockdown is removed and the caches and then Workers in each location receive the udpated status and slowly start to let traffic pass through to the origin again. This is particularly handy at the start of the month when all of our users get their brand new quota and the flood gates open!