
We've just deployed some mega updates to our infrastructure at Report URI that will give us much more resilience in the future, allow us to apply updates to our servers even faster, and will probably go totally unnoticed from the outside!

Our previous Redis setup
I've talked about our infrastructure openly before, but I will give a brief overview of what we were working with and why I wanted to upgrade. We were using Redis in two places, one instance for our application session store, which is fairly self explanatory, and one instance for our inbound telemetry cache. Both of these isolated instances of Redis have been upgraded in the same way, but I will focus on the telemetry cache as this is the one that faces a significant amount of load! Here's how it works.
Visitors head to the websites of our customers, and they may or may not send some telemetry to us depending on whether there are any security, performance or other concerns to report to us about the website they were visiting. These telemetry events are received and are placed directly in to Redis because there are simply too many for us to process them in real-time. Our servers, that we refer to as 'consumers', will then feed telemetry from this Redis cache and process it, applying normalisation, filtering, checking it against our Threat Intelligence, and doing a whole heap of other work, before placing it in persistent storage, at which point it becomes available to customers in their dashboards. This 'ingestion pipeline' can take anywhere from 20-30 seconds during quiet periods, and spike up to 6-7 minutes during our busiest periods, but it is reliable and consistent.
If you'd like to see some real data about the volumes of telemetry we process, what our peaks and troughs look like, and a whole bunch of other interesting metrics, you should absolutely check out our Public Dashboard. That has everything from telemetry volumes, client types, regional traffic patterns, a global heat map and even a Pew Pew Map!!
A single point of failure
Both of our caches, the session cache and the telemetry cache, were single points of failure, and it's never a good idea to have a single point of failure. We've never had an issue with either of them, but it's been something I've wanted to address for a while now. Not only that, but it makes updating and upgrading them much harder work too. The typical process for our upgrades has been to bring up a new server, fully patch and update it and then deploy Redis along with our configuration, with the final step being a data migration consideration. Using Ansible to do the heavy lifting makes this process easier, but not easy. The session cache of course needs a full data migration and then the application servers can flip from the old one to the new one, which isn't so bad because the data is relatively small. The telemetry cache is a little trickier because it involves pointing the inbound telemetry to the new cache, while allowing the consumers to drain down the old telemetry cache before moving them over too. As I say, it's not impossible, but it could be a lot better, and we still have that concern of them both being a single point of failure.
Redis Sentinel to the rescue!
You can read the official docs on Redis Sentinel but I'm going to cover everything you need to know here if you'd like to keep reading. Redis Sentinel provides a few fundamental features that we're now leveraging to provide a much more resilient service.
Monitoring: Redis Sentinels can monitor a pool of Redis caches to determine if they are healthy and available.
Failover: Redis Sentinels will promote and demote Redis caches between the roles of Primary and Replica based on their health.
Configuration: Clients connect to a Redis Sentinel to get the ip/port for the current Primary cache.
Leveraging these features, we've now created a much more robust solution that looks like this:
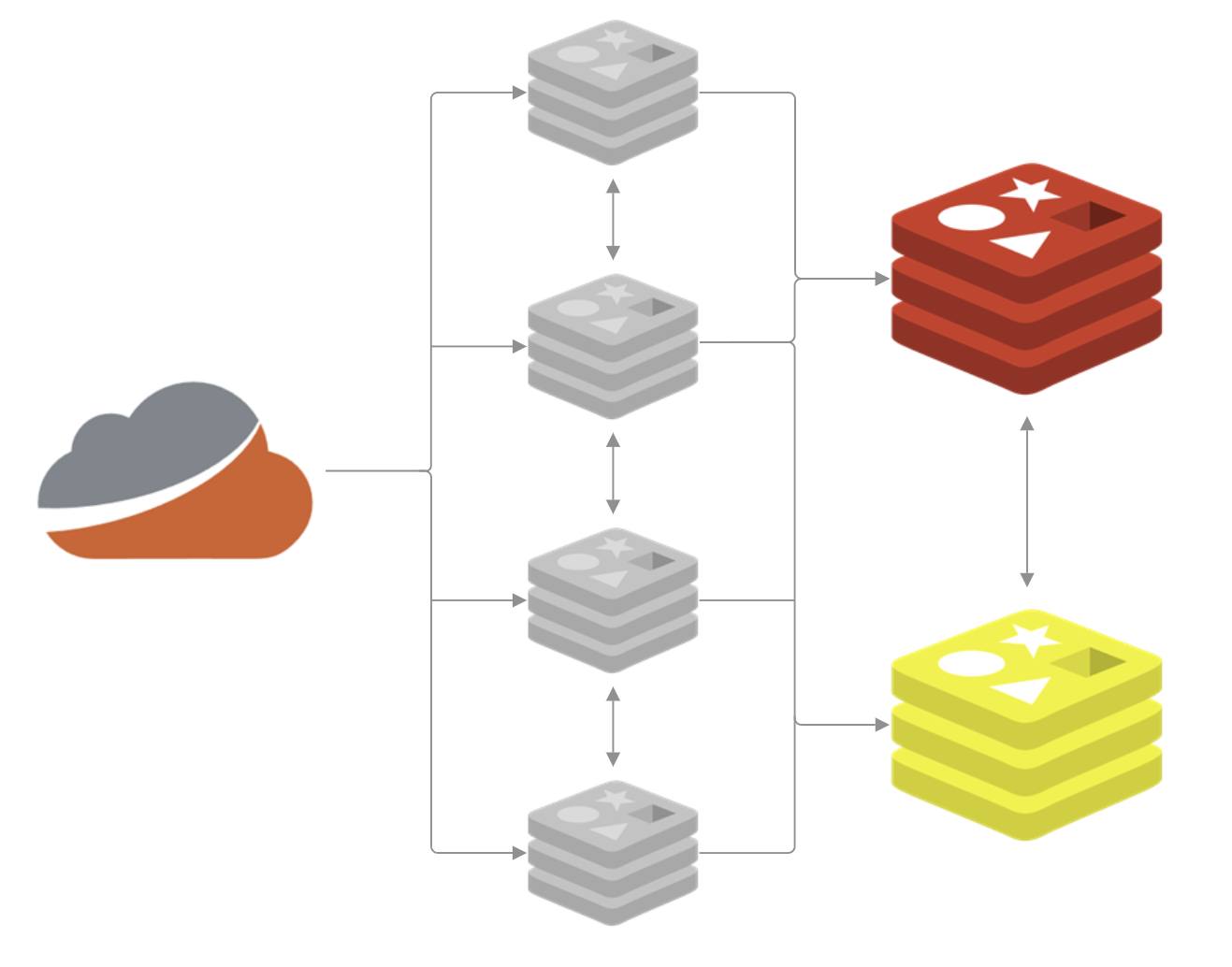
To give an overview of what's happening here, I will break it down in to the following:
Redis Caches: These have an assigned role of either Primary or Replica, and for the purposes of our diagram, the red one will be the Primary and the yellow one will be the Replica. If you have more than two caches in your pool, there would be more Replicas. The role of the Replica is to keep itself fully aligned with the Primary so it can become the Primary at any point if needed. The role of the Primary is to serve the clients as their Redis cache and is where our inbound telemetry is being sent.
Redis Sentinels: These severs do a few things, so let's break it down.
- They're providing ip/port information to clients about which cache is the current Primary. Clients don't know about the caches or how many there are, nor do they know which one is the Primary, so they first ask a Sentinel which cache is the current Primary and then connect to that one. Note that no cache activity passes through the Sentinels, all they do is provide the information to the client on where to connect, and the client will then connect directly to the cache.
- They're monitoring the health of the Primary and Replica/s to detect any issues. If a problem is detected with the Primary, it is put to a vote to see if a Replica should be promoted to Primary. Our configuration requires a quorum of 3/4 votes to successfully promote a Replica to Primary, and demote the Primary to a Replica when it returns. Once that happens, the Sentinels will reconfigure all caches to follow the new Primary, and start providing the new Primary ip/port information to clients.
- They're always monitoring for the addition of new caches or Sentinels. There is no configuration for how many Sentinels or caches there are, they are discovered by talking to the current Primary and getting information on how many Replicas and Sentinels are connected to that Primary.
Failing over
Of course, all of this work is designed to give us a much more resilient solution, and it will also make our work for installing updates and upgrades much easier too. There are two scenarios when the Sentinels can failover from a Primary to a Replica, and they are when the Sentinels detect an issue with the Primary and vote to demote it, or when we manually trigger a failover.
When we're getting ready to do some upgrades, the first step will be to take the Replica down so the Sentinels notice and remove it as an option for a current failover. We can then update/upgrade that server and bring it back online as a viable Replica. Now, when we want to upgrade the cache that is the current Primary, we trigger the failover and the Sentinels will take care of it, meaning our infrastructure now looks like this with the new roles.
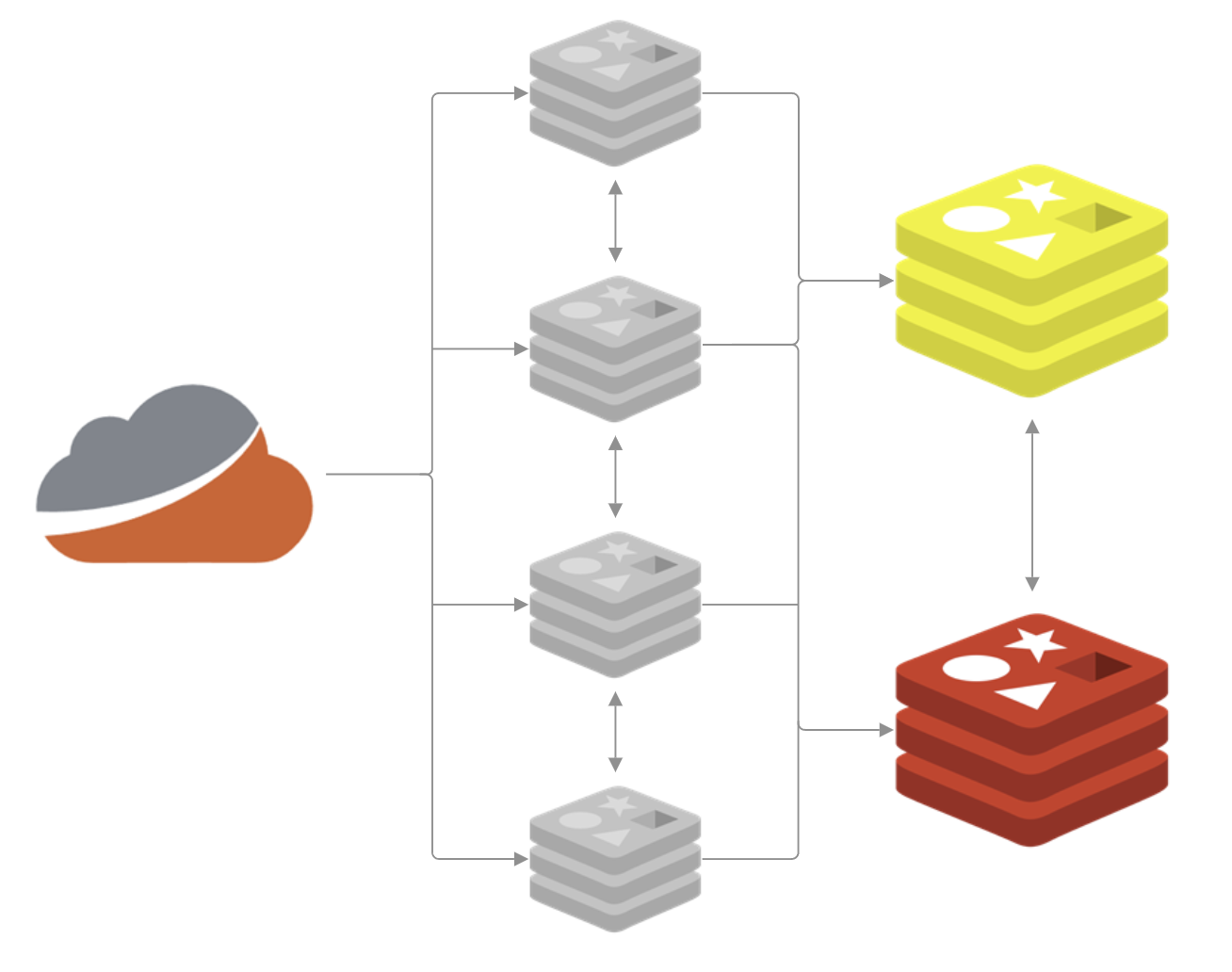
If there is a problem with the update/upgrade, we can immediately fail back, giving us a nice recovery option, and if everything goes well, we can now follow the same process of taking the Replica down for updates/upgrades. Once that's done, both servers are fully updated with considerably less work than before!
Other considerations
Whilst working through this project there were a few little details that I picked up along the way that might be useful to share, and also some that are probably a bit more specific to our deployment.
- Our Redis Sentinels are running on dedicated servers, but I saw many recommendations to co-locate a Redis Sentinel service alongside the Redis Server service on the cache servers themselves. I decided against this for a couple of reasons. First, I didn't want to lose a Sentinel when we took a cache down for updates/upgrades because this will impact the total number of Sentinels available to clients, and it has implications for voting too. Second, I wanted to take that load away from the caches so they could focus on being caches, meaning each of our servers is focusing on doing one thing well.
- Your quorum for voting must be >50% of the number of Sentinels you have, it must be a majority vote to promote a new Primary. With our four Sentinels, if we had a quorum of two, we have less protection against something called a Split-Brain happening. As an example, let's say we have two caches, Redis Cache 1 and Redis Cache 2. Two of our four Sentinels have a transient network issue and see the Primary (Redis Cache 1) as being down, so they vote between themselves to promote a Replica (Redis Cache 2), and then begin that process. Because they can't communicate with the previous Primary (Redis Cache 1), they can't demote it to a Replica. Meanwhile, the other two Sentinels see no issue and continue as normal with their existing Primary (Redis Cache 1). You now have Sentinels providing ip/port information for two different Primaries that are both accepting writes from clients and their data is now diverging, a Split-Brain! Having a quorum require a majority of your Sentinels to vote doesn't fully solve this issue, but it does give you a lot more protection against it.
- If you have a very read-heavy workload, your Replicas can share the load as they do support read-only connections. In our two scenarios we can't really leverage this benefit, which is a real shame, but being able to distribute reads across your replicas may be a huge benefit to you.
Nobody would know!
Whilst this was quite a huge change on our side, from the outside, nobody would know anything about this if I hadn't published this blog post! Going forwards, this will allow me to sleep a lot better knowing we have a more resilient service, and that our future updates and upgrades will now take much less time and effort than before. If you have any feedback or suggestions on our deployment, feel free to drop by the comments below.