
Operating an online service like Report URI, it comes with the territory. The ever present threat of attack is something we are fully aware of, and prepare for as best we can. Being the regular subject of attacks, mostly handled by our robust systems and automated defences, these attacks mostly go unnoticed, but not the most recent one!

Transparency is at our core
I've been open about how things work at Report URI since the beginning, almost a decade ago. How the service has grown and scaled, technical evolutions of our infrastructure, and even the bad bits like incidents and failures, warts and all. This time around is no different and while, as you'll see soon, this wasn't a particularly notable incident with any real impact, I still want to maintain that transparency that we've demonstrated since the beginning.
For those with concerns, let me address those before I dig into the juicy technical details and the changes we've made as a result of the attack. Here's the TLDR;
We were subjected to several attempted DDoS attacks, and the first cohort didn't even raise an alarm, but on the 23rd Jan, we noticed the first impact. For a period of time, our report ingestion servers were heavily loaded and we began to down-sample inbound telemetry. We will often do this for individual customers if they have deployed a misconfiguration and are sending excessive volumes of telemetry, for example, but it is not a regular occurrence at the service level. During this period of time, customers still received telemetry, but at a reduced rate due to the downsampling. This attack subsided without any additional impact.
On the 25th Jan the attack ramped up again, but this time, they were targeting our web application and not our report ingestion servers. I've covered our infrastructure in various posts before, most recently this one, but our web app and our ingestion servers run on completely isolated infrastructure. As the attack ramped up, we were already aware and mitigating, but there was a period of ~11 minutes where unauthenticated users were not able to visit our site. If you were logged in and authenticated during this time, you were able to use our site as normal.
That's the TLDR of the attacks, and there was no other impact, so it was pretty benign overall, but also quite impressive that they were able to bring enough force to bear to have the impact they did!
The ransom demand!
Another interesting twist in this tale, and perhaps the most valuable lesson that many can take away from this, is that we also received a ransom demand during the 25th Jan attack that was clearly nonsense. My guess is that the DDoS attack was a ploy to cause panic and confusion with the goal of rushing us into paying the ransom, a common tactic that the industry sees on a regular basis. Do not fall for these tactics! As the email was sent to my personal email address, I'm sharing it here in my personal capacity for the benefit of everyone. Maybe you've seen the name before, or some of these contact details, or maybe you're just curious what a ransom email might look like!
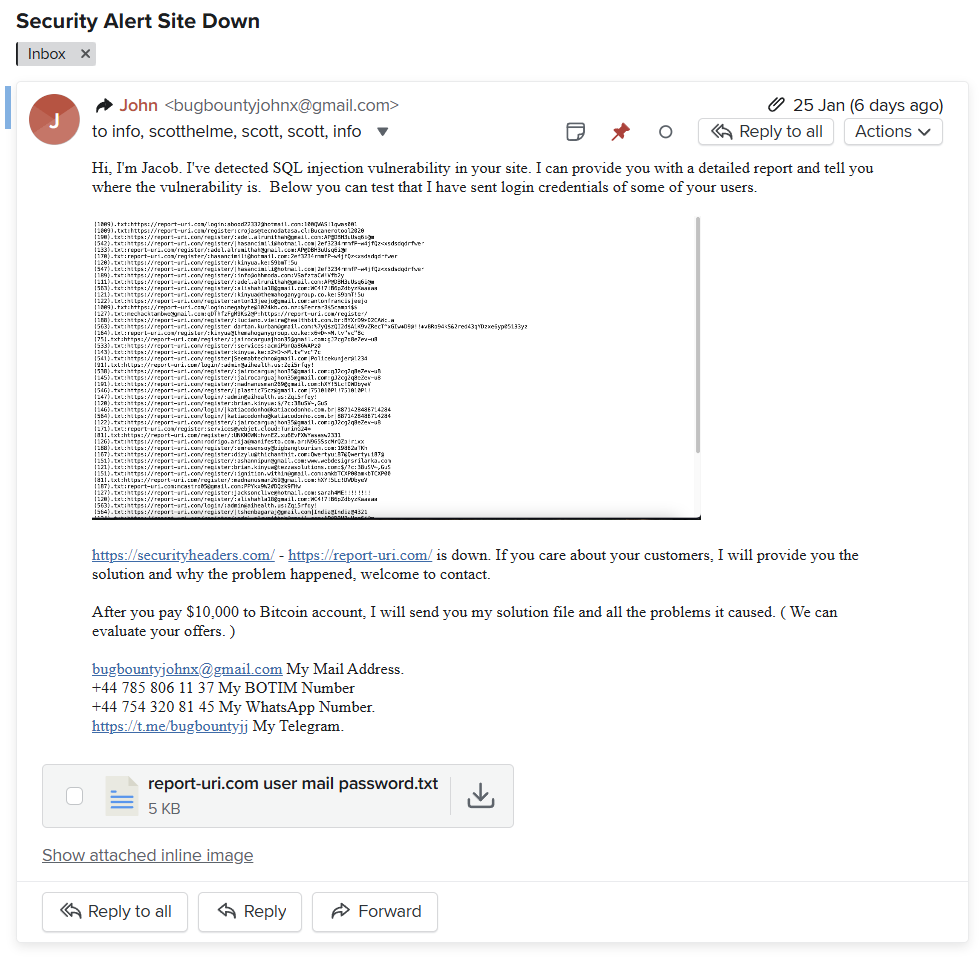
For those familiar with our infrastructure, which poor Jacob clearly isn't, we don't even use a SQL database, so this idea that someone had found a SQL Injection vulnerability is quite entertaining! Despite that, there was a screenshot and a text file containing what was alleged to be the credentials of some of our users. Despite having no faith that this data was real, it's very easy for us to verify this, so that's exactly what we did. None of the email addresses presented in the data were registered users of our service. I was still curious though, where did this data come from?
There's only one person you turn to when you have questions about stolen credential data, and that is, of course, Troy Hunt from Have I Been Pwned!

I was able to quickly reach out to Stefán Jökull Sigurðarson, a good friend, fellow conference speaker and security nerd, along with being, Employee 1.0 at HIBP. I provided the data for him to verify and of course, it came back to a common, recent breach that was completely unrelated to Report URI. This was stolen data that Jacob was trying to pass off as having come from us. His claims were false.
Collaborating with law enforcement
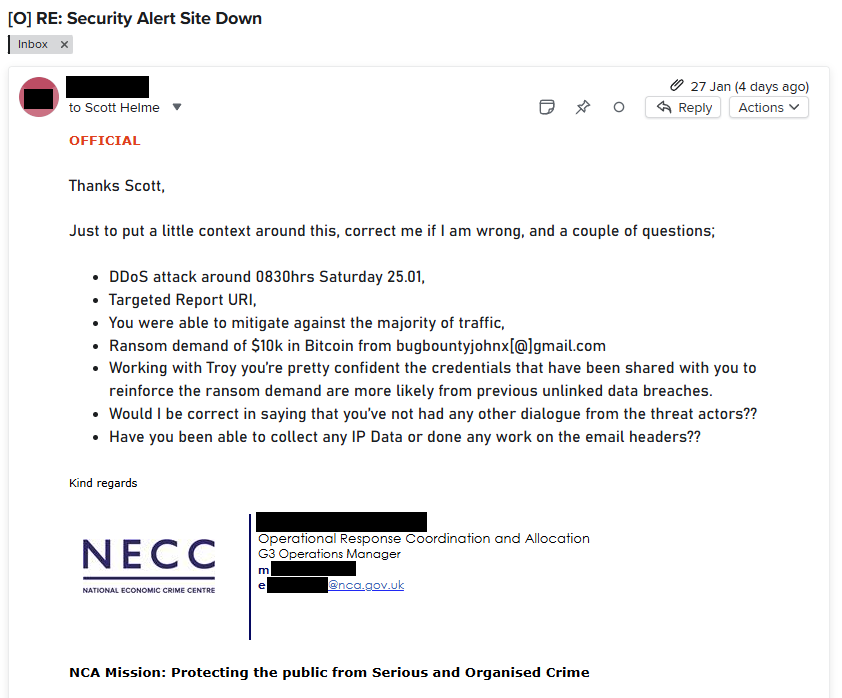
Despite there being no meaningful impact on our service, and having conclusively proven the claims of a data breach to be false, I still felt there would be value in passing details along to law enforcement.

The relevant authority for us to contact in the UK is the National Crime Agency, and having good contacts in this space, I was able to hand over all data that I thought might be worthwhile very quickly. Maybe the only outcome is to know that Jacob has made these threats elsewhere, and that they can be treated with an appropriate level of scepticism, or maybe nothing will come of it at all, but I felt it important to do what we can nonetheless.
With those aspects of this story now nicely covered off, it's time to dig into the technical details and the remediation steps we've already taken, and those that we plan to take!
Sessions for everyone! Or maybe not...
Like most everyone, we use cookies at Report URI to maintain authenticated state in the otherwise stateless protocol that is HTTP. When you visit our site, you can see the __Host-report_uri_sess cookie is set, and this is the cookie we use to tie to the session identifier in our session store.
Our session store is run on a dedicated Redis instance hosted on our private network, and it's quite a sizeable server given that it's only job is to host our session store. Still, though, this is one area of our infrastructure where we don't mind slightly overprovisioning, making it all the more surprising that this is the part of our infrastructure that hit issues first.

As an in-memory data store, Redis is very capable of high performance operation, which is why we use it for our session store, we want the fastest possible session store we can have. Being an in-memory data store, though, Redis isn't typically geared towards persistence of data, but it does offer some persistence options. The Redis cache that handles our inbound report data, which now exceeds 1,000,000,000 telemetry items per day, has no persistence configured. This cache is designed to buffer the insane amount of inbound telemetry we receive while our consumer servers feed from the cache and process the telemetry into persistent storage in Azure Table Storage. Our session cache though, that does have persistence configured.
We use the Redis Database persistence option detailed in the Redis Persistence docs. When configured, Redis will dump a copy of the in-memory store to disk as a snapshot on a frequency that you can control. Here's our Redis config for snapshotting:
################################ SNAPSHOTTING ################################
#
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 1000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
#save 900 1
#save 300 10
save 60 1000We have our Redis session cache configured to take a snapshot and save it to disk every 60 seconds if at least 1,000 keys have changed in the cache. This is a fairly reasonable config that gives us some persistence if there was ever an issue with the in-memory store, and we could recover with minimal loss. Given the hardware resources of the server, I was surprised to see the following errors starting to be reported.
14618:M 25 Jan 09:26:58.034 * 1000 changes in 60 seconds. Saving...
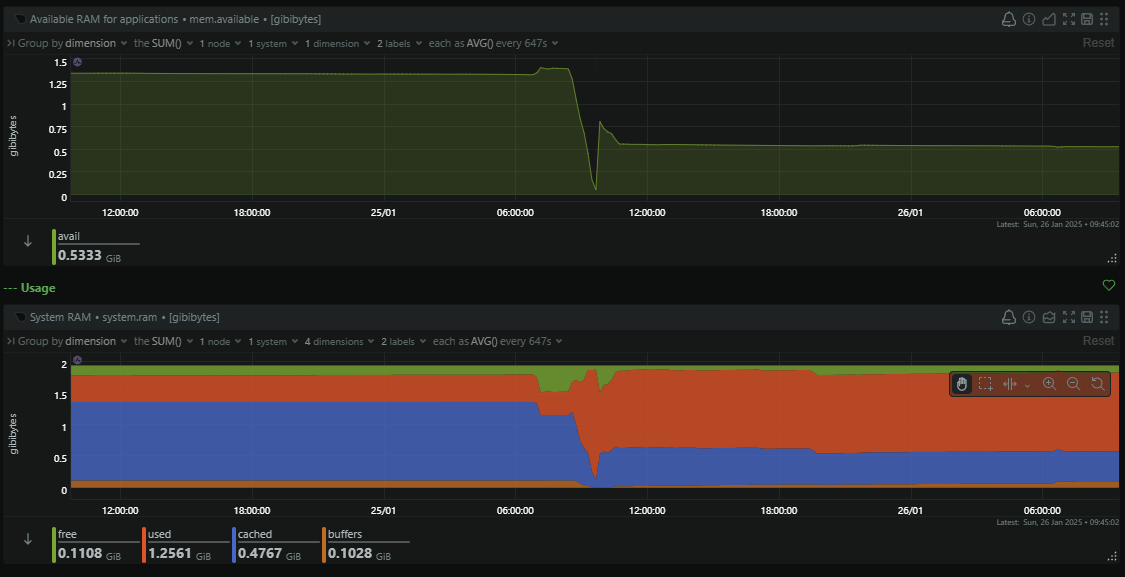
14618:M 25 Jan 09:26:58.034 # Can't save in background: fork: Cannot allocate memoryIt's odd because first, the server has an enormous amount of RAM that apparently we were low on, and second, I hadn't received any notifications that the server was low on resources, which is something I'd receive a notification about immediately. Something didn't add up, and I was quickly able to verify that the server was only using a little over 50% of the available RAM, so we still had a huge amount left.
My first thought was how does Redis generate the snapshot and save it to disk. If Redis was trying to create a duplicate of the data in memory, to then dump it to disk, that could explain it, but it didn't make sense as we'd see regular swings in the consumption of RAM on the server, something that the monitoring did not show.
Reading the docs a little more I was able to confirm that Redis forks and while the parent process continues to serve clients, the child process dumps the data to disk and then exits. To avoid having to make a duplicate of the data in memory for the child to dump to disk, Redis uses the 'copy-on-write' semantic of the fork() system call. This is a really awesome way of avoiding the inconvenience and resource consumption of duplicating the data just to dump it to disk and then erase it. In short, all of the data in memory is marked as read-only, the kernel will intercept writes to the data and create a new memory location to write the incoming data, leaving the original data intact for the child process to read and dump to disk. There's a nice summary here in the man page for fork(), but this left me wondering why are we struggling with memory allocation given that fork() should have minimal impact on the memory resources of the server... It turns out, there's an FAQ for that!
The kernel is responsible for keeping track of memory resources on the system and it has three 'accounting modes' it can use to keep track of that virtual memory and manage it.
/proc/sys/vm/overcommit_memory
This file contains the kernel virtual memory accounting
mode. Values are:
0: heuristic overcommit (this is the default)
1: always overcommit, never check
2: always check, never overcommitThe default mode here, mode 0, is what is causing our issue with the Redis process fork(). Despite using the copy-on-write semantic, it is theoretically possible that the Redis child process created during the fork will need to create a full duplicate of the data in memory, and the systems does not have enough memory to accommodate that once >50% of the RAM has been consumed, which is why the fork() call fails, causing the failure of the snapshot. Now, that's no big deal, right? We can't dump a copy of the data to disk, but the cache should still be functional. There's just one default config option we need to look at in Redis:
# By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error yesBy default, if the Redis snapshot fails, Redis will disable writes to the cache to preserve the data as it is no longer being backed up, and this is the point at which new sessions for authenticated users on the website can't be created. All existing sessions and data are there, and can be read, but when new sessions are created, well, they can't be, because the write to the cache will fail. This is the crux of the issue and why for a period of ~11 minutes, visitors to the site may have experienced an error.
Improvement in session handling
Having read the previous section, it will probably be obvious what most of the remediation steps are going to be, so I will summarise them here to give an overview of what we've done, and what we're going to do.
The first step was to resolve the immediate issue with the session cache, and that was to ensure to cache would keep working even if the snapshot process fails. I disabled this config option on the live server.
config set stop-writes-on-bgsave-error noThe next step was to then persist this change in the config file so that the behaviour will remain even after Redis next restarts.
# By default Redis will stop accepting writes if RDB snapshots are enabled
# (at least one save point) and the latest background save failed.
# This will make the user aware (in a hard way) that data is not persisting
# on disk properly, otherwise chances are that no one will notice and some
# disaster will happen.
#
# If the background saving process will start working again Redis will
# automatically allow writes again.
#
# However if you have setup your proper monitoring of the Redis server
# and persistence, you may want to disable this feature so that Redis will
# continue to work as usual even if there are problems with disk,
# permissions, and so forth.
stop-writes-on-bgsave-error noFinally, we needed to allow the Redis process to successfully fork() even when the server has <50% of RAM remaining by changing how the kernel was accounting for memory. Changing to mode 1 will allow the kernel to overcommit on memory usage during the fork() and we can rely on the copy-on-write to prevent us from exceeding available RAM.
root@redis-session-cache:~# cat /proc/sys/vm/overcommit_memory
0
root@redis-session-cache:~# echo 1 > /proc/sys/vm/overcommit_memory
root@redis-session-cache:~# cat /proc/sys/vm/overcommit_memory
1The final thing that we're going to change, which is almost complete at the time of writing, requires a little development work and testing. When a visitor hits our site, we create a session for them in the session cache, which in hindsight isn't really necessary, nor even a good idea. We're changing our session handling so that once deployed, a session will only be created in the cache, and a cookie assigned to the user, after a successful authentication. This would mean that the millions upon millions of hits against our website wouldn't have had any impact on our session cache, because without a successful authentication, there would never be any communication with Redis at all. Here's a screen capture of me navigating around the test site with our existing functionality, and you can see the cache hits against Redis in the background.
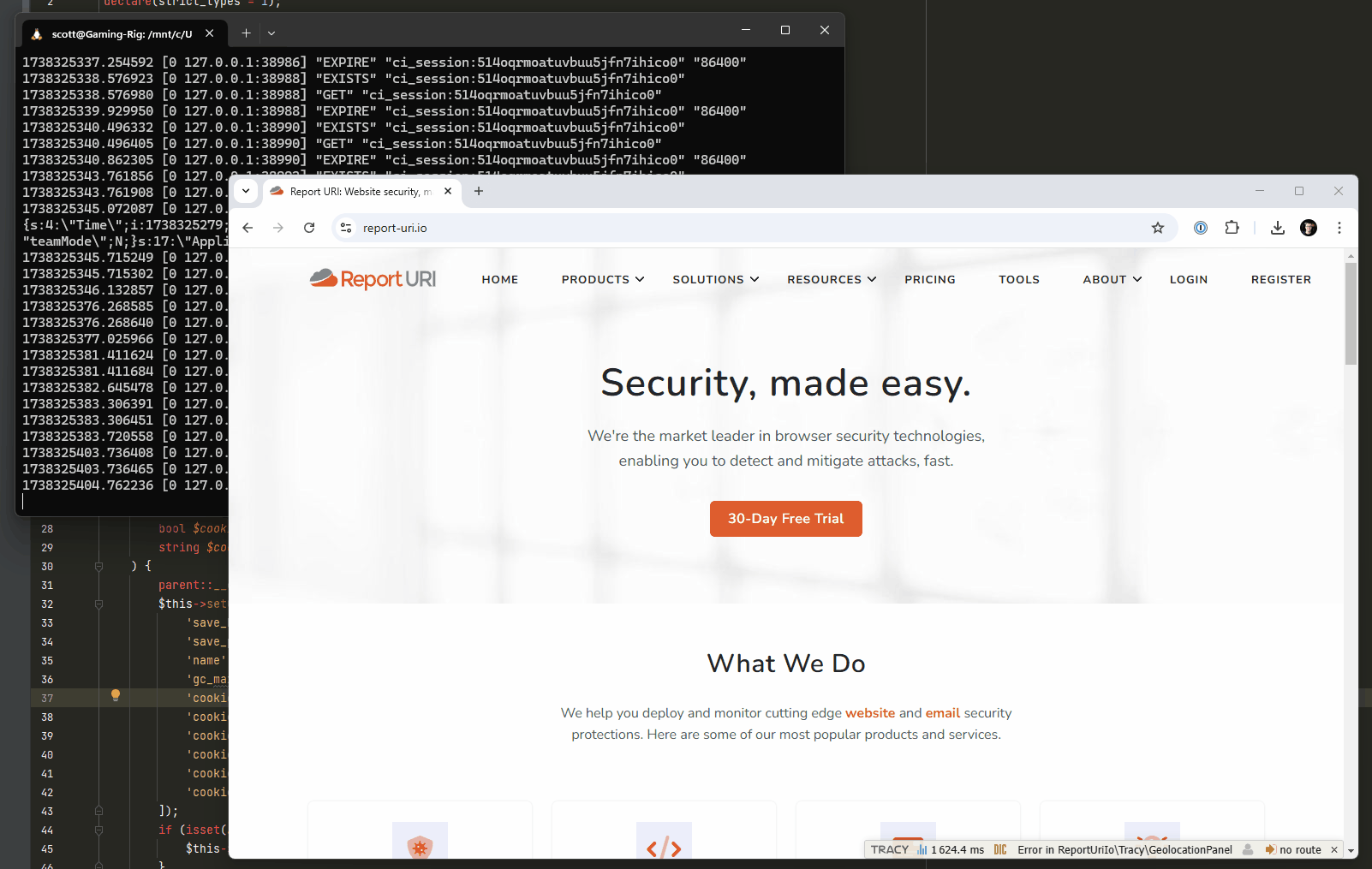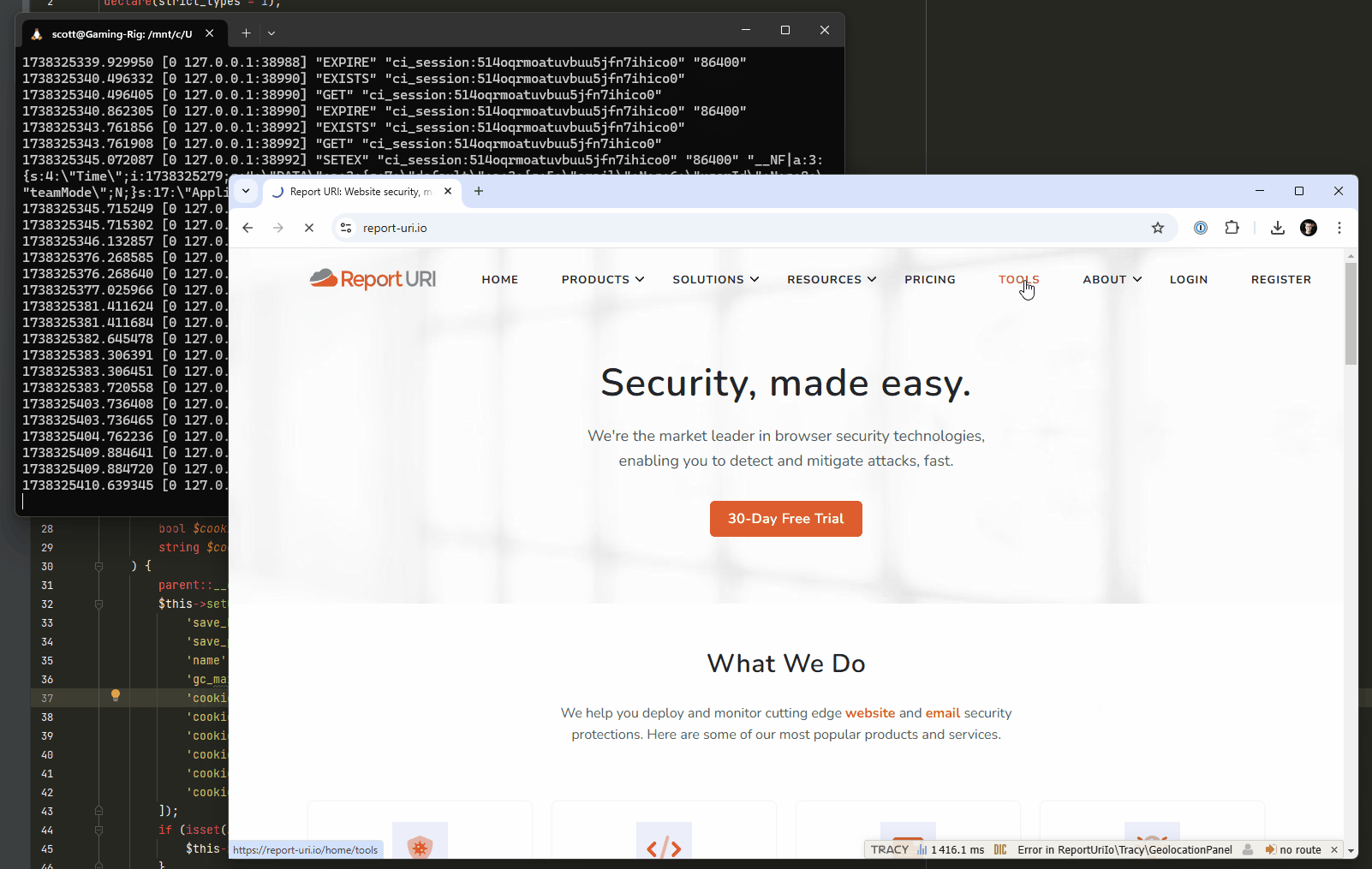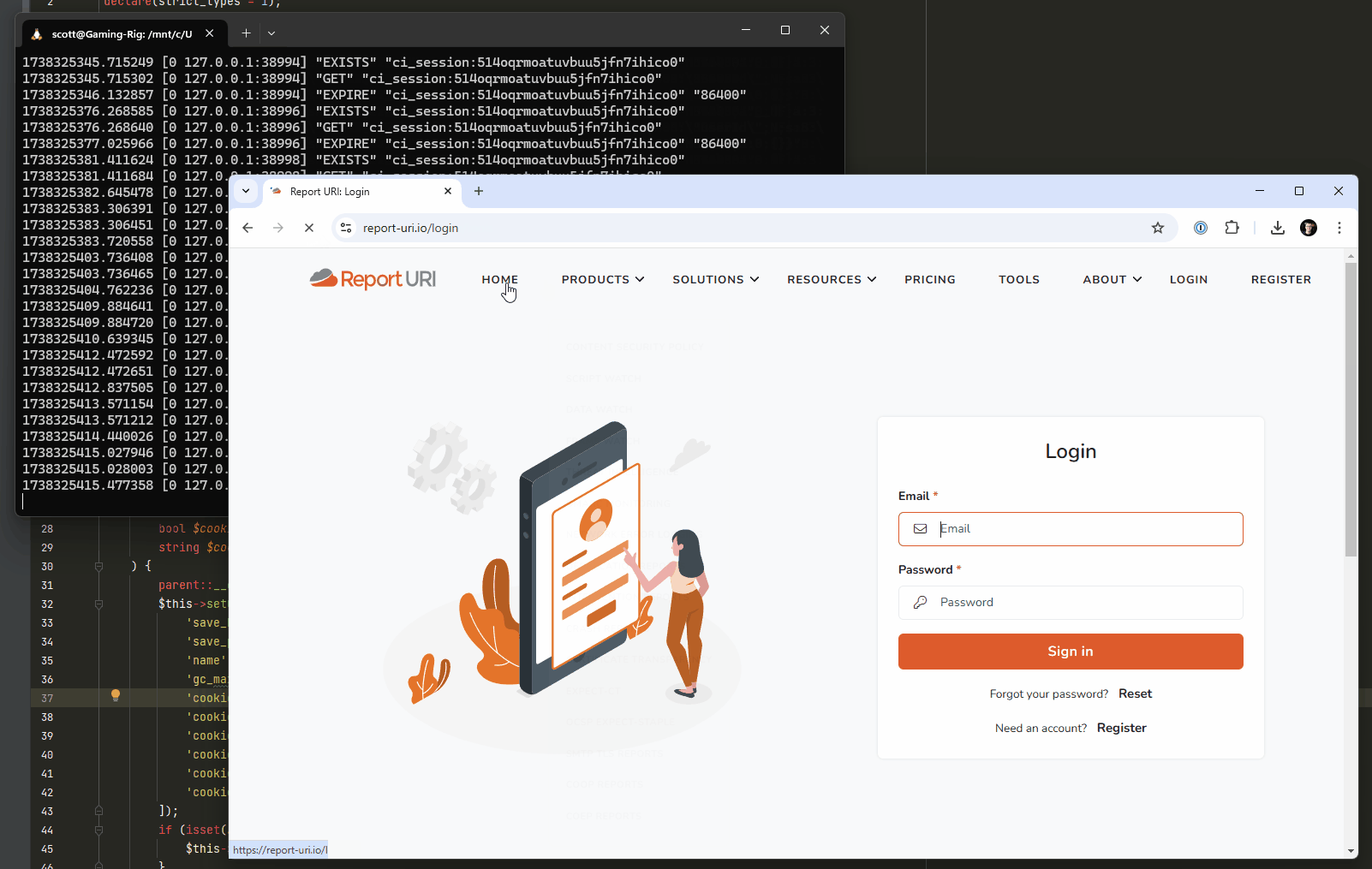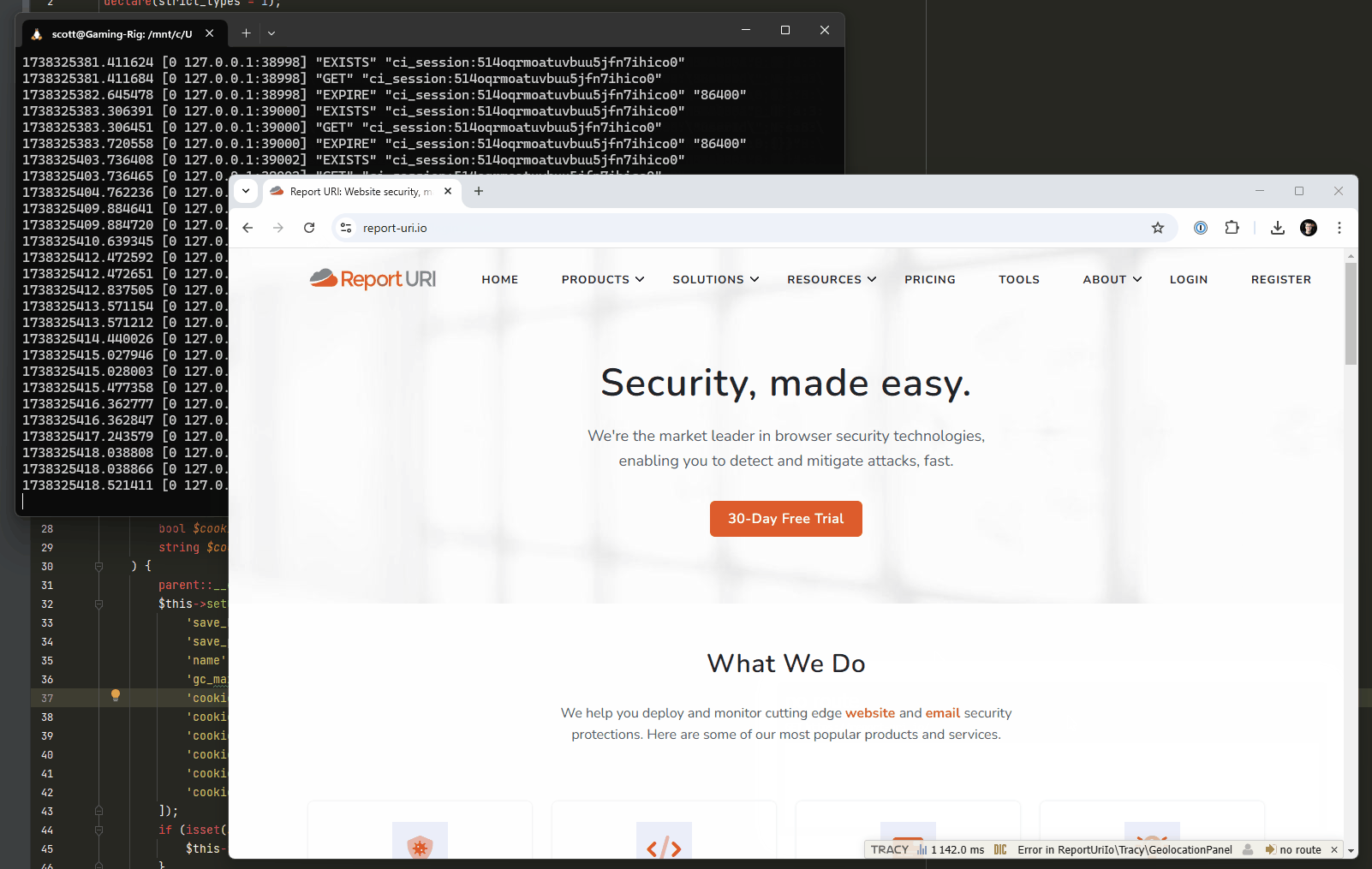
With the new change deployed, visitors to the site won't have a session created and won't be issued a cookie until after a successful authentication, resulting in no activity against the session cache.
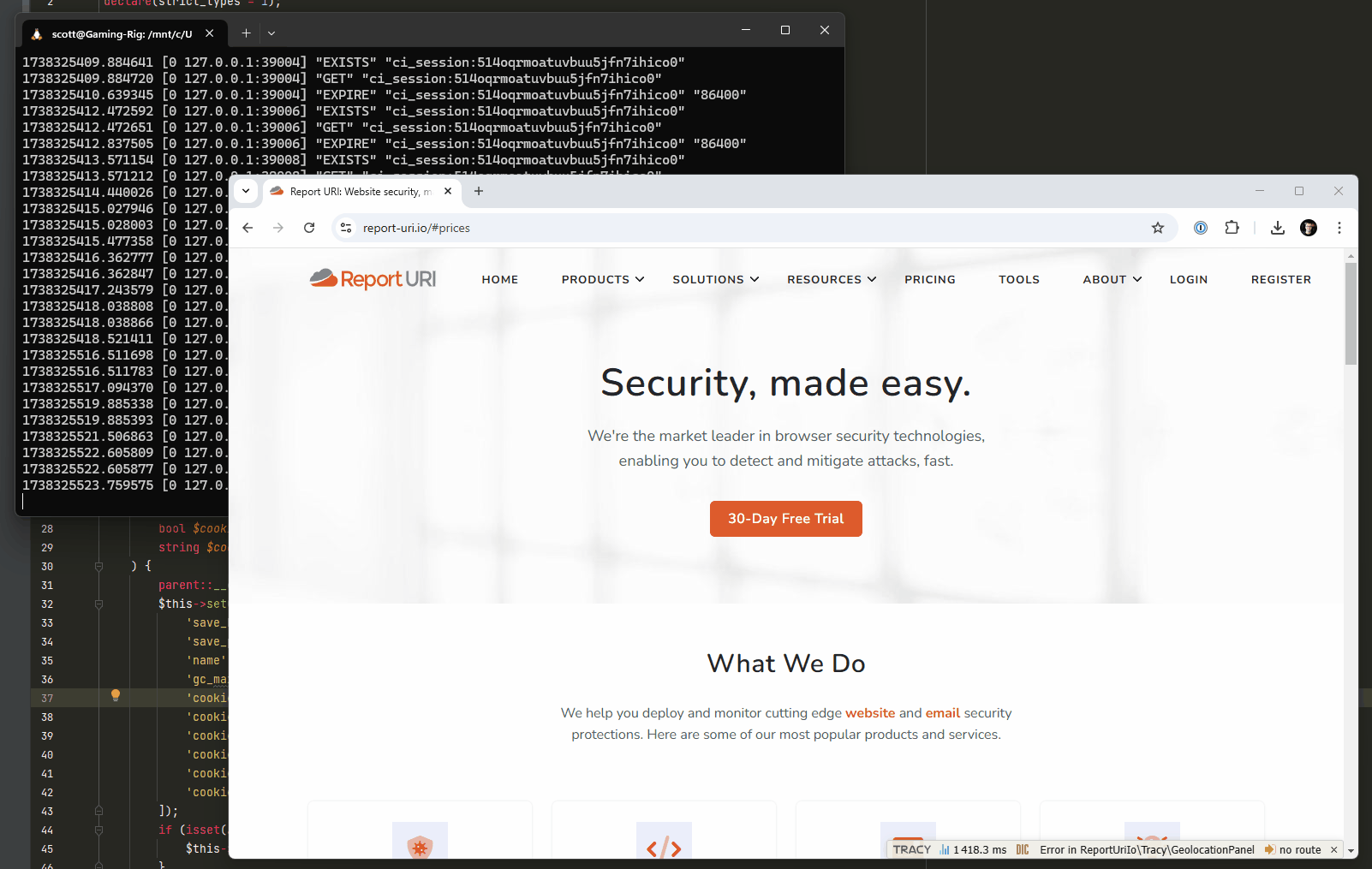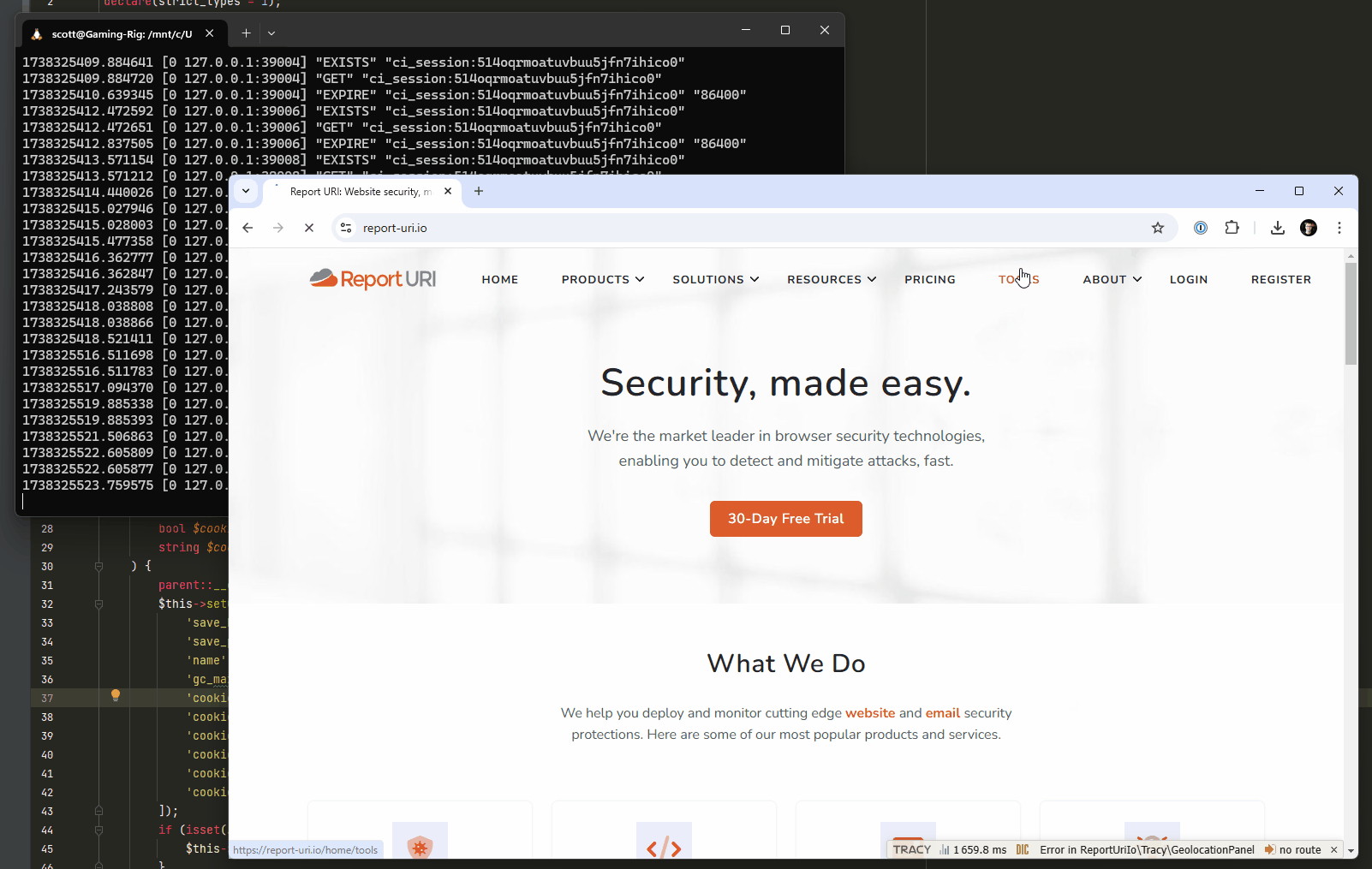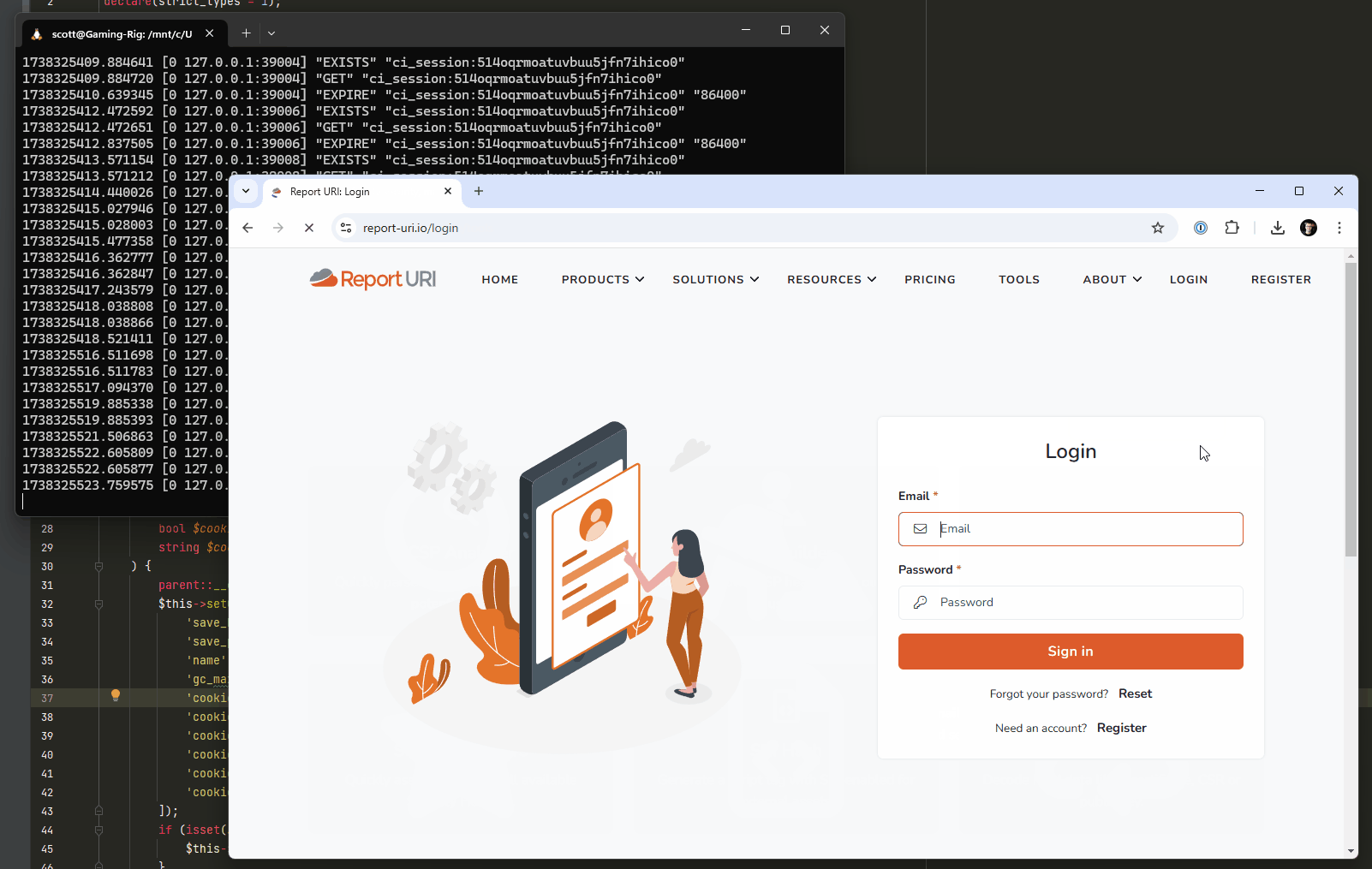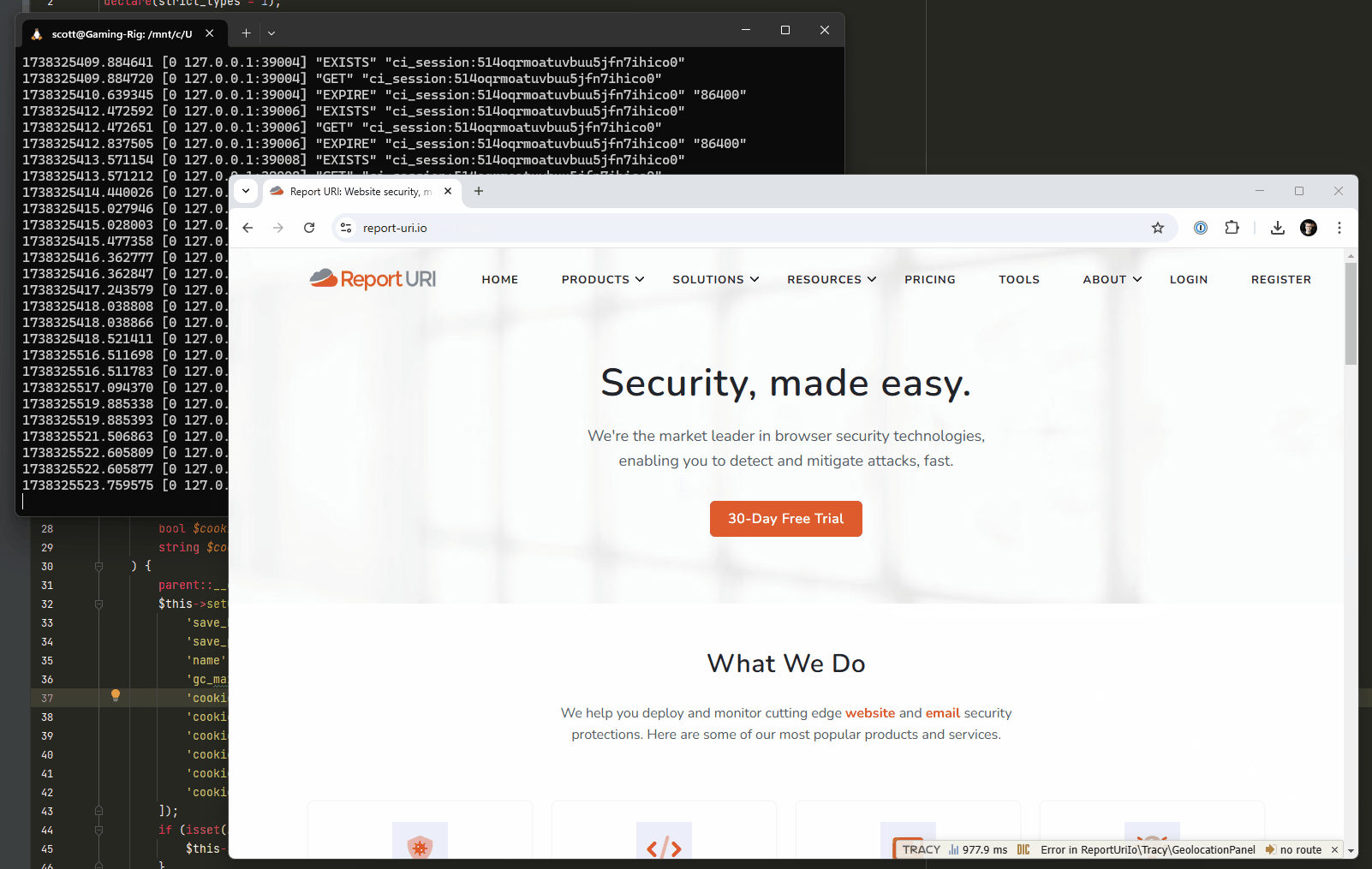
I'm hoping to have this change out in the next week or so, after it's had some extensive testing, and it will certainly help should we find ourselves in a similar situation again.
Tightening our DDoS protections
As regular readers will know, we make extensive use of Cloudflare's services at Report URI, from caching and CDN services, to bot and DDoS mitigation, Workers, and more. Whilst we have the DDoS mitigation services in place, no protection is ever 100% effective and, of course, a small portion of the traffic did make it through to our origin servers, causing the issues above. Here are our firewall events for the attack on 25th Jan, showing the quite obvious period of time that the attack took place:
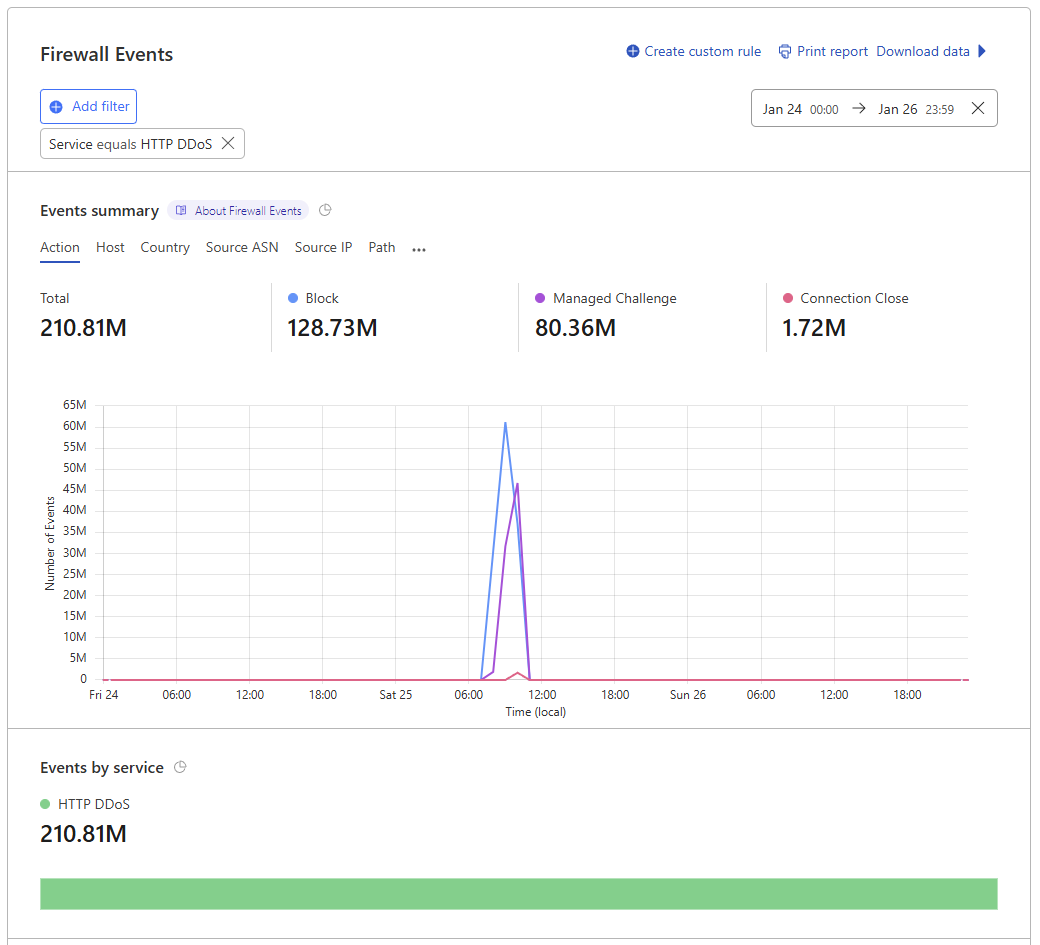
The attack that happened on the 23rd Jan was much smaller in volume, but was made up of mostly POST requests with telemetry data sent to our ingestion endpoints, causing a different kind of load, but still an inconvenience.
Now that we have a sizeable sample of data to work with, I've been working my way through and outlining our plan for tightening these controls. As is often the case with security, this a balancing act of trying to block as much malicious traffic as we can, without adversely impacting legitimate users. This will be a much slower process of making small tweaks and observing their impact over time, but as we go, our rules will become more resilient and more effective at stopping the kind of attacks we're seeing. I'll probably write this process up as a separate blog post as this one is already getting quite large, and so far we've only taken the first steps in starting to tighten our WAF rules, so keep an eye out for that in the future.
Onwards and upwards
Neither of these attacks really had any meaningful impact, none of our data was ever at risk, and most people won't have even noticed anything happened. Despite that, I still wanted to talk about this issue openly, to show our commitment to transparency, but also, to talk about some interesting technical challenges! Maybe you and your organisation will face a similar issue in the future and you can be more aware of the ransom scam, maybe the lessons we learned here are something you can use to avoid similar issues of your own in the future, or maybe this blog post was just an interesting read for you. Either way, these things happen, they happen to everyone, and they're likely to keep on happening, so here's to hoping that we can all share and learn from these experiences.